一.Trails 说明
理论知识在系列一里有说明,这里在拿出来看一下:
To support thecontinuous extraction and replication of database changes, Oracle GoldenGatestores the captured changes temporarily on disk in a series of files called a trail.A trail can exist on the source or target system, or on an intermediary system,depending on how you configure Oracle GoldenGate. On the local system it isknown as an extract trail (or local trail). On a remote system it is known as aremote trail.
--为了支持连续的extraction 和 replication 数据的改变,GG抓取这些改变的数据临时存放在一系列的磁盘文件里, 这些文件就叫trail。 Trail 文件可以放在Source或者Target system里,甚至可以放到转换的系统上,这主要取决与GG 的配置,如果存放在local system上,就叫extract trail 或者 localtrail,如果存放在remote system上就叫作remote trail。
By using a trailfor storage, Oracle GoldenGate supports data accuracy and fault tolerance. Theuse of a trail also allows extraction and replication activities to occurindependently of each other. With these processes separated, you have morechoices for how data is delivered. For example, instead of extracting and replicatingchanges continuously, you could extract changes continuously but store them inthe trail for replication to the target later, whenever the target applicationneeds them.
通过使用trail,GG 支持精确的数据同步和故障处理。
1.1 Processes that write to, and read, a trail
The primaryExtract process writes to a trail. Only one Extract process can write to atrail.
Extract 进程可以将capture data 写入trail。只允许一个Extract进程写入一个trail。
Processes that read the trail are:
以下2个进程可以读取trail 文件:
(1) Data-pump Extract: Extractsdata from a local trail for further processing, if needed, and transfers it tothe target system or to the next Oracle GoldenGate process downstream in theOracle GoldenGate configuration.
(2) Replicat: Reads a trail toapply change data to the target database.
Data pump 说明,可以参考:
1.2 Trail maintenance
Trail files arecreated as needed during processing, and they are aged automatically to allowprocessing to continue without interruption for file maintenance. By default,trails are stored in the dirdat sub-directory of the Oracle GoldenGatedirectory.
--Trail 文件在进程运行时创建,trail 在使用时允许进程在不中断的情况下进行维护。 默认情况下,trails存放在GG 安装目录的dirdat 子目录下。
By default, eachfile in a trail is 10 MB in size. All file names in a trail begin with the sametwo characters, which you assign when you create the trail. As files arecreated, each name is appended with a unique, six-digit serial (sequence)number from 000000 through 999999, for example c:\ggs\dirdat\tr000001. When thetrail sequence number reaches 999999, the numbering starts over at 000000.
--默认情况下,每个trails 文件为10MB,所有的trails由2个相同的字母开头,当创建trail时,每个trail 文件名有我们指定的2个字母加6个数字组成,这样来进行唯一性约束。 6个数字从000000 到999999. 当数字到达999999时,又继续从000000开始。
You can createmore than one trail to separate the data from different objects or applications.You link the objects that are specified in a TABLE or SEQUENCE parameter to a trailthat is specified with an EXTTRAIL or RMTTRAIL parameter in the Extractparameter file.
--可以创建多个trail 文件已分别存放不同对象的trail。
Aged trail filescan be purged by using the Manager parameter PURGEOLDEXTRACTS.
--使用中的trail 文件可以使用Manager 参数:PURGEOLDEXTRACTS进行清空。
1.3 How processes write to a trail
To maximizethroughput, and to minimize I/O load on the system, extracted data is sent intoand out of a trail in large blocks. Transactional order is preserved. Bydefault, Oracle GoldenGate writes data to the trail in canonical format, aproprietary format which allows it to be exchanged rapidly and accurately amongheterogeneous databases. However, data can be written in other formats that arecompatible with different applications.
--为了最大的吞吐量和最小的系统I/O, trail 文件的写入和读取都是按large block 进行。 默认情况下,GG 写入trail 的文件的内容都是特定的格式,特定的格式可以实现快速的exchange 和 不同数据库之间实现精确的同步。当然也可以根据不同的应用,按照不同的格式进行写入。
By default,Extract operates in append mode, where if there is a process failure, arecovery marker is written to the trail and Extract appends recovery data tothe file so that a history of all prior data is retained for recovery purposes.
默认情况下,Extract是append 模式,如果一个process 失败,在下次启动Extract 时,recovermarkder 可以写入这个trail,进行Extract recovery操作,但是这个启动Extract的过程会比较长。关于这个Extract recovery 的监控,在以下链接的1.1 小结有说明。
In append mode,the Extract initialization determines the identity of the last complete transactionthat was written to the trail at startup time. With that information, Extract endsrecovery when the commit record for that transaction is encountered in the datasource; then it begins new data capture with the next committed transactionthat qualifies for extraction and begins appending the new data to the trail. Adata pump or Replicat starts reading again from that recovery point.
--在append 模式下,在启动Extract 初始化时,会在trail中找到last completetransaction的位置。然后从这个位置开始进行recovery,直到在data source里遇到commitrecord,就结束Extract Recovery。Extract 正常启动。 Extract 进程正常启动之后,就可以正常的以append 方式写入新的capturedata。
Data pump 进程或者Replicat 进程从Recover point 开始读取data。
这个last complete transaction 可以理解为recover point,因为GG 也是根据归档和onlineredo 来的,所以这个recovery 过程也是从DB 的log里进行判断,找到了commit record,即GG和 DB 的log 一致,结束recovery 过程。
这段recovery 出来的tail data 还没有发送到target 上或者还没有应用,所以Data pump 或 replicat 进程从这个recovery point 开始恢复。
在恢复阶段,我们查看Extract 进程的状态,就显示为APPEND。
这一段ExtractRecovery 过程是根据自己的理解来写的,可能不完全正确,有其他理解的可以互相讨论。
Overwrite modeis another version of Extract recovery that was used in versions of Oracle GoldenGateprior to version 10.0. In these versions, Extract overwrites the existing transactiondata in the trail after the last write-checkpoint position, instead ofappending the new data. The first transaction that is written is the first onethat qualifies for extraction after the last read checkpoint position in thedata source.
--Overwrite 模式的Extract Recovery 是GG 10.0版本之前使用的。 Extract 重写trail中已经存在,并在lastwrite-checkpoint position之后的transaction data,代替了append new data。
If the versionof Oracle GoldenGate on the target is older than version 10, Extract will automaticallyrevert to overwrite mode to support backward compatibility. This behavior canbe controlled manually with the RECOVERYOPTIONS parameter.
--如果Target GG的版本小于10,ExtractGG的版本大于10,为了兼容性, Extract 将自动转换成overwrite 模式。 可以通过RECOVERYOPTIONS参数手工的控制这种自动转换的功能。
1.4 Trail format
As of OracleGoldenGate version 10.0, each file of a trail contains a file header recordthat is stored at the beginning of the file. The file header containsinformation about the trail file itself. Previous versions of Oracle GoldenGatedo not contain this header.
在GG 10.0版本里,每个trailfile 包含一个file header,其用来存储beginning of file。 10.0 版本之前的GG 不包含header。
Each data recordin a trail file also contains a header area, as well as a data area. The recordheader contains information about the transaction environment, and the dataarea contains the actual data values that were extracted.
每条trail file的record中包含一个headerarea和data area。 Record 的headerarea 包含transaction environment,data area 包含实际的的extracteddata。
Trail 的格式在第二部分具体进行说明。
二.Trails 中record format
我们可以通过GG 自带的logdump 工具来查看trails 文件的具体格式。
2.1 logdump 工具使用说明
MOS 上有关logdump的2篇文档:
How To Save A Part Of A GoldenGate Trail ToA New Trail [ID 966188.1]
Oracle GoldenGate - Using the GoldenGateLogdump Utility to Manually Load Balance across Multiple Processes [ID1301300.1]
2.1.1 进入GG 安装目录,运行logdump命令。
cgg1:/home/oracle> cd /u01/ggate/
gg1:/u01/ggate> logdump
Oracle GoldenGate Log File Dump Utility
Version 11.1.1.1OGGCORE_11.1.1_PLATFORMS_110421.2040
Copyright (C) 1995, 2011, Oracle and/or itsaffiliates. All rights reserved.
Logdump 1 >
2.1.2 set up the view –建立logdump环境
(1)To view the record header with thedata:
Logdump 1 >ghdr on
(2)To add column information
Logdump 2 >detail on
-- Column informationincludes the number and length in hex and ASCII.
(3)To add hex and ASCII data values to the column information:
Logdump 3 >detail data
(4)To view user tokens:
Logdump 4 >usertoken on
(5)To control how much record data is displayed:
Logdump 5> RECLEN <length>
Logdump 5 >reclen 1000
Reclen set to 1000
2.1.3 To open a trail file 打开文件
(1)指定trail 文件
Logdump 6 >open /u01/ggate/dirdat/lt000008
Current LogTrail is/u01/ggate/dirdat/lt000008
(2)To go to the first record and thenmove through records in sequence:
Logdump 7>NEXT or N
示例:
Logdump 7 >n
___________________________________________________________________
Hdr-Ind : E (x45) Partition : . (x04)
UndoFlag : . (x00) BeforeAfter: A (x41)
RecLength : 45 (x002d) IO Time : 2011/11/1713:11:28.000.000
IOType : 5 (x05) OrigNode : 255 (xff)
TransInd : . (x00) FormatType : R (x52)
SyskeyLen : 0 (x00) Incomplete : . (x00)
AuditRBA : 23 AuditPos : 16783888
Continued : N (x00) RecCount : 1 (x01)
2011/11/17 13:11:28.000.000 Insert Len 45 RBA 1009
Name: DAVE.BL
After Image: Partition 4 G b
00000006 0000 0002 424c 0001 0006 0000 0002 3839 | ........BL........89
00020015 0000 3230 3131 2d31 312d 3137 3a31 333a | ......2011-11-17:13:
30393a32 34 | 09:24
Column 0 (x0000), Len 6 (x0006)
00000002 424c | ....BL
Column 1 (x0001), Len 6 (x0006)
00000002 3839 | ....89
Column 2 (x0002), Len 21 (x0015)
00003230 3131 2d31 312d 3137 3a31 333a 3039 3a32 | ..2011-11-17:13:09:2
34 | 4
2.1.4 To go to a specific RBA in the file定位
(1)To go to an RBA anywhere in the file:
Logdump 9> POS <rba>
Logdump 10> N
示例:
GGSCI (gg1) 8> info ext1
EXTRACT EXT1 Last Started 2011-11-1910:02 Status RUNNING
Checkpoint Lag 11:49:46 (updated 00:00:06 ago)
Log Read Checkpoint Oracle Redo Logs
2011-11-18 22:12:21 Seqno 26, RBA 22834688
Logdump 10 >pos 22834688
Reading forward from RBA 22834688
Logdump 11 >n
--因为当前的extract使用的trail 文件不是lt000008,所以这里没有显示结果。
(2)To go to the first record in the file:
Logdump 11> POS FIRST
或
Logdump 11> POS 0
示例:
Logdump 12 >pos 0
Reading forward from RBA 0
Logdump 13 >n
2011/11/17 13:08:42.353.436 FileHeader Len 942 RBA 0
Name: *FileHeader*
30000199 3000 0008 4747 0d0a 544c 0a0d 3100 0002 | 0...0...GG..TL..1...
00023200 0004 2000 0000 3300 0008 02f1 d81a ab92 | ..2... ...3.........
1f1c3400 0014 0012 7572 693a 6767 313a 3a75 3031 | ..4.....uri:gg1::u01
3a676761 7465 3600 001c 001a 2f75 3031 2f67 6761 | :ggate6...../u01/gga
74652f64 6972 6461 742f 6c74 3030 3030 3038 3700 | te/dirdat/lt0000087.
00010138 0000 0400 0000 0839 0000 0800 0000 0000 | ...8.......9........
001b493a 0000 8107 3133 3633 3532 3200 0000 0000 | ..I:....1363522.....
00000000 0000 0000 0000 0000 0000 0000 0000 0000 | ....................
00000000 0000 0000 0000 0000 0000 0000 0000 0000 | ....................
00000000 0000 0000 0000 0000 0000 0000 0000 0000 | ....................
2.1.5 To filter based on a table name
(1)To filter out everything exceptrecords containing a specific table name:
Logdump 14> FILTER INCLUDE/EXCLUDEFILENAME <schema>.<table>
Now, when you use the N command, you willonly see records that satisfy this filter.
(2)To remove the current filtercriteria
Logdump14> FILTER CLEAR
(3)To filter on multiple conditions
Logdump 14> FILTER INCLUDEFILENAME <schema>.<table>; FILTER RECTYPE <record_type>;FILTER MATCH ALL
2.1.6 To count the records in a trail file
Logdump 14> COUNT
示例:
Logdump 14 >count
LogTrail /u01/ggate/dirdat/lt000008 has 37records
Total Data Bytes 3834
AvgBytes/Record 103
Insert 34
RestartOK 1
DDL 1
Others 1
After Images 36
Average of 4 Transactions
Bytes/Trans ..... 1402
Records/Trans ... 9
Files/Trans ..... 1
Partition 0
Total Data Bytes 1153
AvgBytes/Record 576
RestartOK 1
DDL 1
After Images 2
*FileHeader* Partition 0
Total Data Bytes 942
AvgBytes/Record 942
Others 1
DAVE.BL Partition 4
Total Data Bytes 1739
AvgBytes/Record 51
Insert 34
After Images 34
2.1.7 To save records to a new trail file
(1)To save the whole file:
Logdump 15> SAVE <file>
Where: <file> is the name of the newfile.
(2)To save a subset of records:
Logdump15> SAVE <file> <n>RECORDS
To close the current file and open the nextone in the trail
Logdump 15> NEXTTRAIL
2.1.8 To keep a log of your session
(1) To start logging:
Logdump 15> LOG TO <filename>.txt
(2)To write text to the log:
Logdump 15> WRITELOG “<text>”
(3)To stop logging:
Logdump 15> LOG STOP
2.1.9 To see the current Logdumpenvironment
Logdump 15> ENV
This shows whichfeatures are enabled, such as filtering and header views, and it showsenvironment information such as the current trail and position.
示例:
Logdump 15 >env
Version : Linux, x64, 64bit (optimized) onApr 21 2011 22:44:06
Current Directory : /u01/ggate
LogTrail : /u01/ggate/dirdat/lt000008
Trail Format : New
End of File : 6985
Current Position : 0 Forward
Next Position : 0
Last Modtime : 2011/11/17 17:16:22.000.000
Display RecLen : 200
Logtrail Filter : On
Show Ghdr : On
Detail : Data
UserToken : On
Trans History : 0 Transactions, Records 100, Bytes100000
LargeBlock I/O : On, Blocksize 57344
Local System : LittleEndian
Logtrail Data : BigEndian/ASCII
Logtrail Headers : ASCII
Dump : ASCII
Savefile comments : Off
Timeoffset : LOCAL
Scan Notify Interval: 10000 records,Scrolling On
2.1.10 To get online command help
Logdump 17> HELP
2.1.11 To exit Logdump
Logdump 17> EXIT
或
Logdump 17> QUIT
2.2 Trails 格式说明
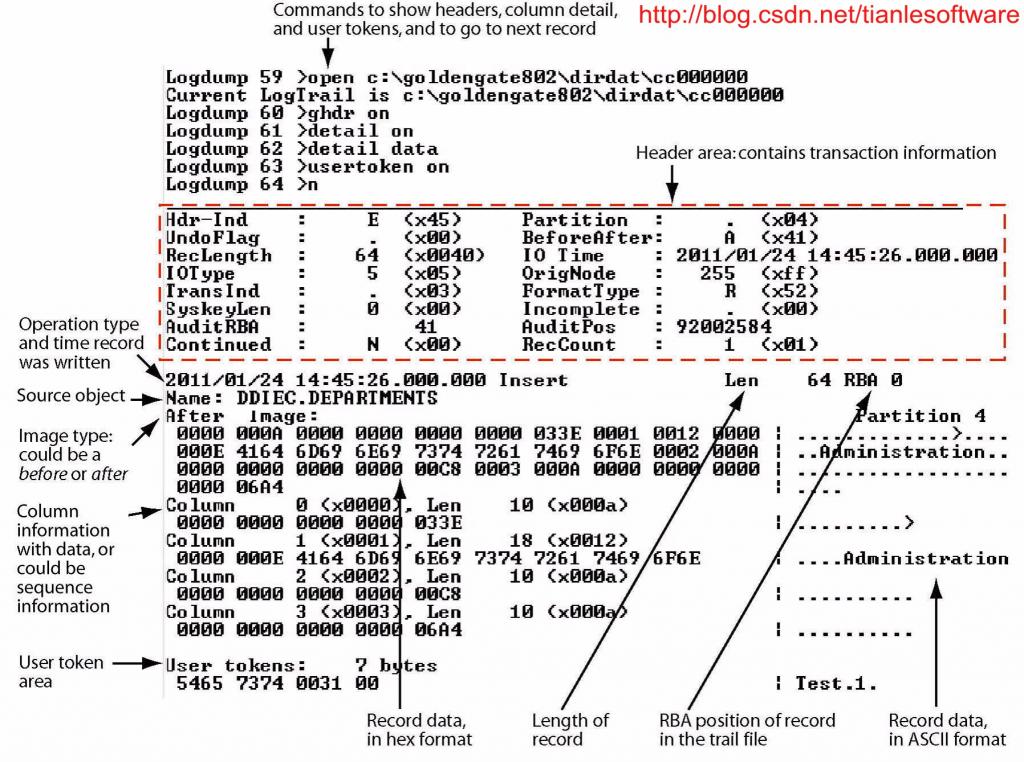
这个是官方文档上的一个图。我们现在来看一下,
2.2.1 Record header area
The OracleGoldenGate record header provides metadata of the data that is contained in therecord and includes the following information.
--GG record header 包含以下内容:
(1) The operation type, such as aninsert, update, or delete
(2) The before or after indicatorfor updates
(3) Transaction information, suchas the transaction group and commit timestamp
2.2.1.1 Description of header fields
The following describes the fields of the Oracle GoldenGate record header. Some fields applyonly to certain platforms.



2.2.1.2 Using header data
Some of the dataavailable in the Oracle GoldenGate record header can be used for mapping byusing the GGHEADER option of the @GETENV function or by using any of the followingtransaction elements as the source expression in a COLMAP statement in the TABLEor MAP parameter.
(1) GGS_TRANS_TIMESTAMP
(2) GGS_TRANS_RBA
(3) GGS_OP_TYPE
(4) GGS_BEFORE_AFTER_IND
2.2.2 Record data area
The data area of the Oracle GoldenGatetrail record contains the following:
Trail 的data area 记录了如下内容:
(1) The time that the change waswritten to the Oracle GoldenGate file
(2) The type of database operation
(3) The length of the record
(4) The relative byte addresswithin the trail file
(5) The table name
(6) The data changes in hex format
The followingexplains the differences in record image formats used by Oracle GoldenGate onWindows, UNIX, Linux, and NonStop systems. The terms “full” and “compressed”image format are used in the descriptions. These terms are used in a differentcontext here than when they are used in other parts of the documentation inreference to how Extract writes column data to the trail, meaning whether onlythe key and changed columns are written (“compressed”) versus whether allcolumns are written to the trail (“uncompressed” or “full image”).
2.2.2.1 Full record image format
Full record imageformat is only generated in the trail when the source system is HP NonStop, andonly when the IOType specified in the record header is one of the following:
--Full record image 格式仅在source system 是HPNonStop,并且在IOTye 指定如下类型时生成:
3 — Delete
5 — Insert
10 — Update
Each full recordimage has the same format as if retrieved from a program reading the originalfile or table directly. For SQL tables, datetime fields, nulls, and other datais written exactly as a program would select it into an application buffer.Although datetime fields are represented internally as an eight-byte timestamp,their external form can be up to 26 bytes expressed as a string. Enscriberecords are retrieved as they exist in the original file.
When theoperation type is Insert or Update, the image contains the contents of therecord after the operation (the after image). When the operation type is Delete,the image contains the contents of the record before the operation (the beforeimage).
--如果是insert 或 update 操作,那么image包含的是after image,即修改之后的data,如果是delete,则保存的beforeimage。
For recordsgenerated from an Enscribe database, full record images are output unless the originalfile has the AUDITCOMPRESS attribute set to ON. When AUDITCOMPRESS is ON, compressedupdate records are generated whenever the original file receives an update operation.(A full image can be retrieved by the Extract process by using the FETCHCOMPS parameter.)
2.2.2.2 Compressed record format
By default,trail records written by processes on Windows and UNIX systems are always compressed.The format of a compressed record is as follows:
<columnindex><column length><column data>[...]
--默认情况下,trail record是compress的,为什么要compress在下一节说明。
Where:
(1) <column index> is the ordinal index ofthe column within the source table (2 bytes).
(2) <column length> is thelength of the data (2 bytes).
(3) <column data> is thedata, including NULL or VARCHAR length indicators.
Enscribe recordswritten from the NonStop platform may be compressed. The format of a compressedEnscribe record is as follows:
<fieldoffset><field length><field value>[...]
Where:
(1) <field offset> is the offset within theoriginal record of the changed value (2 bytes).
(2) <field length> is thelength of the data (2 bytes).
(3) <field data> is the data,including NULL or VARCHAR length indicators.
The first fieldin a compressed Enscribe record is the primary or system key.
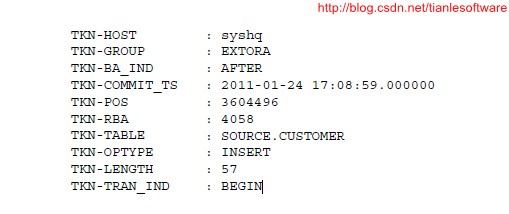
2.2.2.3 Tokens area
The trail recordalso can contain two areas for tokens. One is for internal use and is not documentedhere, and the other is the user tokens area. User tokens are environment valuesthat are captured and stored in the trail record for replication to targetcolumns or other purposes. If used, these tokens follow the data portion of therecord and appear similar to the following when viewed with Logdump:
--trail record 的token 包含2个areas,其中一个供内部使用,文档就不做说明,另一个是user token。
2.2.2.4 Oracle GoldenGate operation types
The followingare some of the Oracle GoldenGate operation types. Types may be added as newfunctionality is added to Oracle GoldenGate. For a more updated list, use the SHOWRECTYPE command in the Logdump utility.




2.2.3 Oracle GoldenGate trail header record
In addition tothe transaction-related records that are in the Oracle GoldenGate trail, each trailfile contains a file header.
--在每个trail file中除了之前讲的trail header,trailarea,还有一个file header。
The file headeris stored as a record at the beginning of a trail file preceding the data records.The information that is stored in the trail header provides enough information aboutthe records to enable an Oracle GoldenGate process to determine whether the recordsare in a format that the current version of Oracle GoldenGate supports.
The trail headerfields are stored as tokens, where the token format remains the same across allversions of Oracle GoldenGate. If a version of Oracle GoldenGate does not supportany given token, that token is ignored. Depracated tokens are assigned a defaultvalue to preserve compatibility with previous versions of Oracle GoldenGate.
You can view thetrail header with the FILEHEADER command in the Logdump utility.
.trail再压缩
在上面一节看到,默认情况下,trails 是compress的。当数据进行异地传输时,网络负载是影响数据传输效率的关键因素。GoldenGate的其中一个优势是,它极大地压缩了传输的trail文件。
在默认压缩(redo=>trail)的基础上,GoldenGate提供了再压缩方案:在传输trail之前对其进行进一步的压缩,然后在写入远端trail之前再进行解压。官方文档中说明这次再压缩的压缩比至少在4:1,实际中压缩比率会更高,有网友测试达10:1。
这里注意GoldenGate的再压缩过程,压缩之后发送到Target 端后,在写入远端trail前又解压了回来,所以单纯比较两端的trail文件大小没有变化。但是在传输过程中确实是压缩了。
这样的设计,可以减少对Replicat进程提取trail的影响,从而也避免了加重原本负载就相对较大的Replicat进程。
GoldenGate的再压缩,是在负责向远端发送trail的Extract进程中配置的,因此一般情况下都是配置在datapump中。配置很简单,在RMTHOST参数中加入COMPRESS子参数,如下:
GGSCI (gg1) 42> view params dpump
extract dpump
userid ggate@gg1, password ggate
rmthost gg2, mgrport7809,compress,compressthreshold 0
rmttrail /u01/ggate/dirdat/lt
passthru
table dave.pdba;
-- COMPRESS启用再压缩,COMPRESSTHRESHOLD表示对大于该值的trail记录块进行压缩,取值0到28000,默认1000,设置为0表示全部进行压缩
启用了压缩后,会消耗额外的CPU,在同步事务量较大的情况下,需要考虑CPU负载。但实际上在大部分的GoldenGate应用场景中,网络负载都远远大于CPU负载,启用trail再压缩的可能性还是很大的。
-------------------------------------------------------------------------------------------------------
版权所有,文章允许转载,但必须以链接方式注明源地址,否则追究法律责任!
Blog: http://blog.csdn.net/tianlesoftware
Weibo: http://weibo.com/tianlesoftware
Email:
Skype: tianlesoftware
-------加群需要在备注说明Oracle表空间和数据文件的关系,否则拒绝申请----
DBA1 群:62697716(满); DBA2 群:62697977(满) DBA3 群:62697850(满)
DBA 超级群:63306533(满); DBA4 群:83829929(满) DBA5群: 142216823(满)
DBA6 群:158654907(满) DBA7 群:69087192(满) DBA8 群:172855474
DBA 超级群2:151508914 DBA9群:102954821 聊天 群:40132017(满)